Smartmiq Desktop Assistant
Spotlight‑style voice assistant for desktop. Trigger actions hands‑free (search, reply to Slack, etc.). I trained my own ASR based on a transducer architecture for tighter control over latency and accuracy.
What I learned: voice on laptops/desktops is useful but often slower than typing in public; UX must bias toward zero‑friction hybrid input (keyboard + voice), and ASR needs strong endpointing.
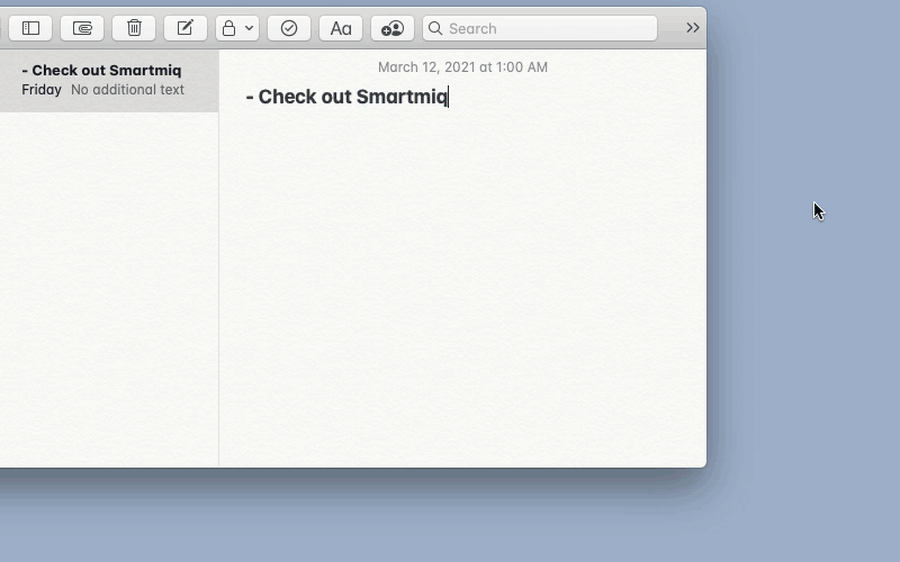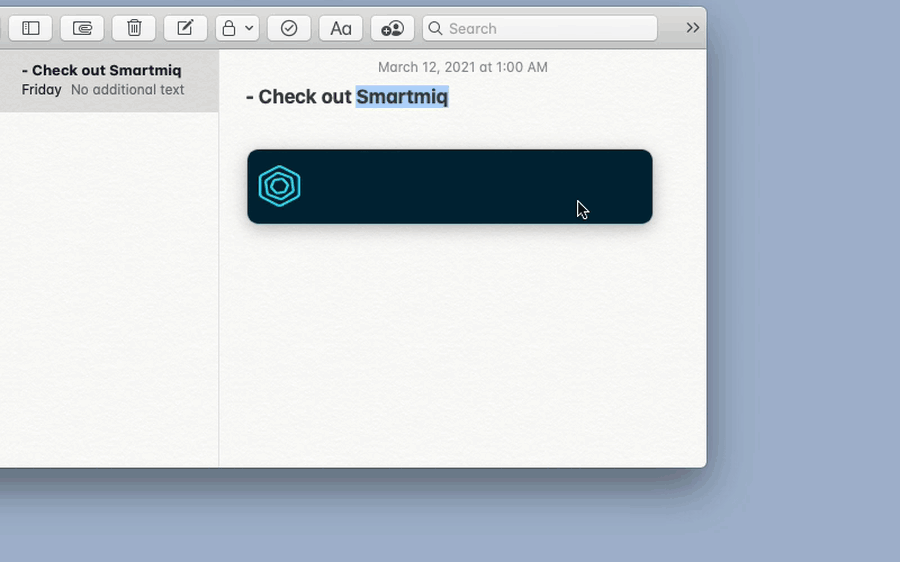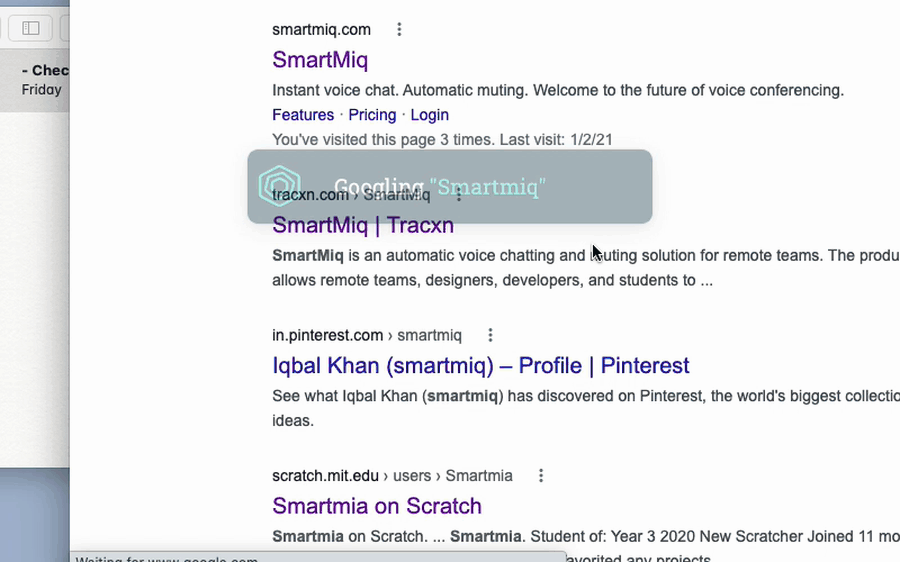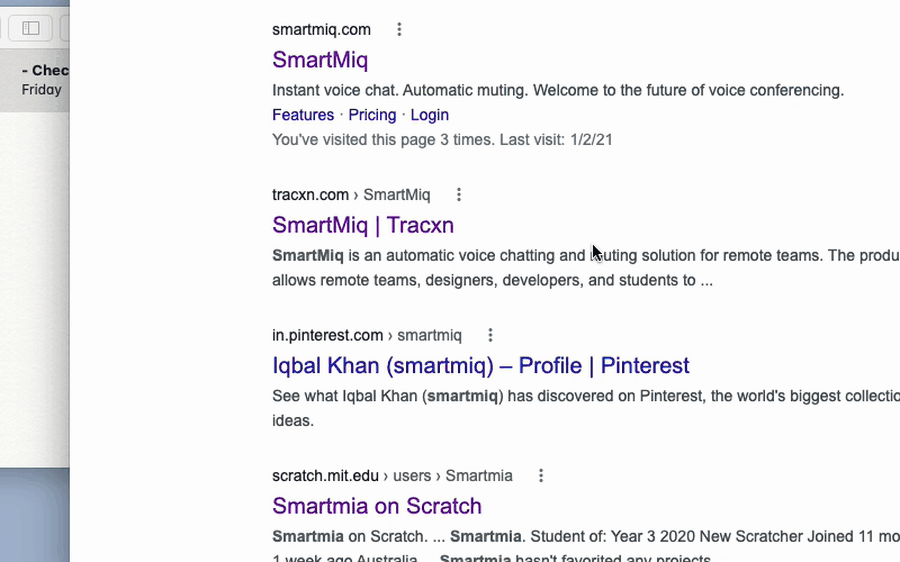
Replying to Slack by voice:

Deep RL plays Pong
Implemented Soft Actor‑Critic with an AtariNet‑style convolutional encoder. Training leveraged replay, MC rollouts, and importance sampling. After tuning entropy targets and augmentation, the agent achieved stable Pong gameplay.
Training code: gist
Noise Suppression Neural Network
Learned a spectral mask to suppress non‑speech noise, inspired by Google’s VoiceFilter. The model improves intelligibility in common home/office environments.
Rover — Music Visualizer via GAN
Mapped audio frequency features to a smoothed latent walk through a pretrained art‑DCGAN to generate synchronized visuals in real time.
- Compute frequency components per frame
- Integrate with previous latent for temporal smoothness
- Render GAN output to framebuffer
Code: github.com/kareemn/rover
Meeting Voice Assistant (Zoom/Meet/Webex)
Before high‑quality meeting audio APIs existed, I emulated webcam/mic drivers in a Dockerized headless Chrome to capture >16kHz audio for wake‑word and ASR, then scaled it across a Kubernetes cluster. We also used a virtual webcam to demo the bot live, a surprisingly effective growth loop.
Poynt Nay‑Nay
Built remote OS/app update tooling for payment terminals; for a stress test we pushed a music video to all test devices at once — chaos ensued.